优化问题之多个传感器(Arduino)按顺序采集的样本
- 通过 Peter Crona
- February 27, 2021
- 科技视点

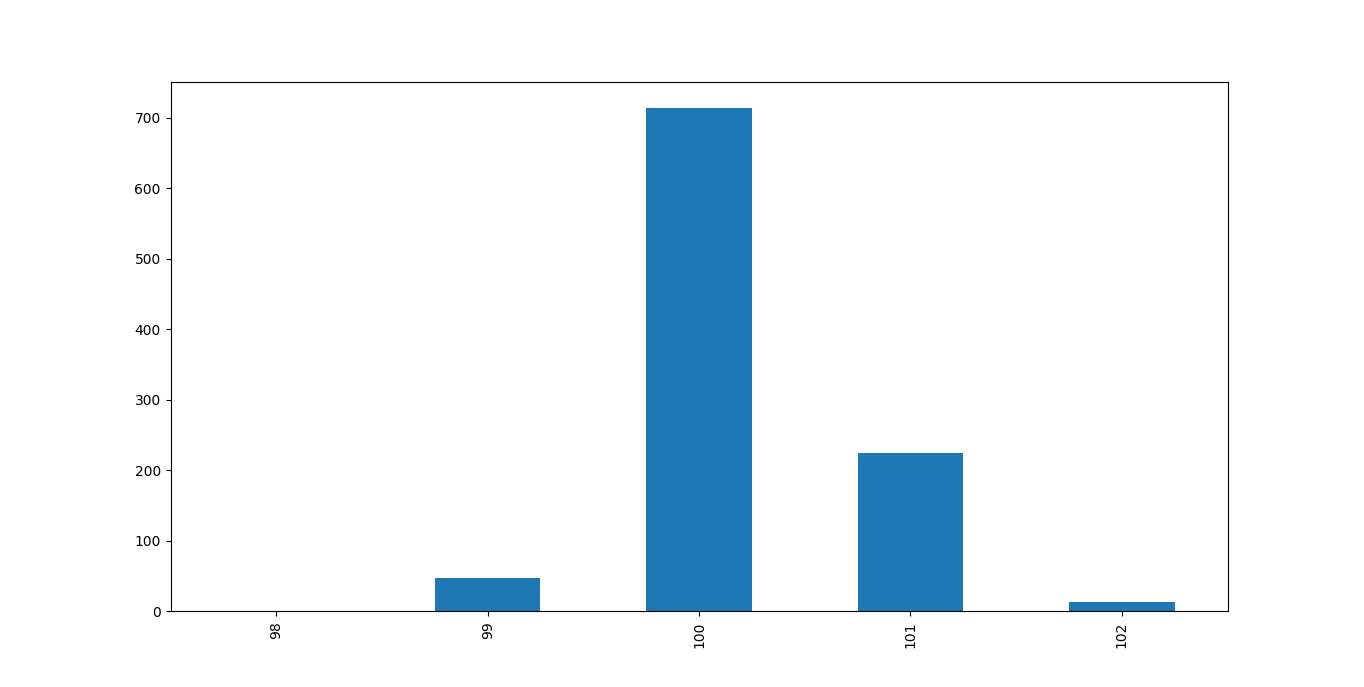
某天醒来突然有个想法,如果选择适量样本来监测空气中污染物浓度时,该如何运用统计学和优化问题来提高监测结果的精确度。实验证明,传感器,至少我实验中使用的传感器,每个传感器花上几毫秒的时间来采集30个样本,会显示一段相当稳定的电压值,或者即使只采集一个样本,也能得到相当不错的结果,也会得到得到一个非常稳定的电压值。其中一个传感器采样时(大约一秒钟)的分布示例如图1所示。
还不想读完全文?那就直接戳编码部分吧!
尽管如此,这于我依旧是一个不错的小项目,既可以练习一些C++编程技术(目前正在阅读 A Tour of C++),也可以练习统计算法和优化问题,因此我继续实践着最初的想法。我们常常已经解决的许多问题总能和未来将遇到的问题有相通之处,所以,我还希望这次实验中使用到的技术可以在之后的项目中派上用场。
当下要解决的问题是我想监测出传感器的模拟输出值。因为我观察到几次模拟输出值的不稳定性,这也正是我所担忧的。然而,在监测中得到了一个稳定的偏差值,约0.5左右,这似乎又不是一个大问题了。我实验中使用的传感器设置如图2所示,它是由一组监测臭氧浓度,湿度和温度的传感器组成。

在这里想为读者们呈现一个黑色MQ131传感器上监测到的模拟输出值图。现在回想起来,因为之前没有被“预热”,的确曾看到了一些凌乱的数据-传感器的使用说明书中也特别指出,传感器如果长时间或从未使用,则需要将其打开几天才会正常运行。尽管如此,用适当的比例对Y轴调整后,数值图看起来仍旧有些混乱,如图3所示。
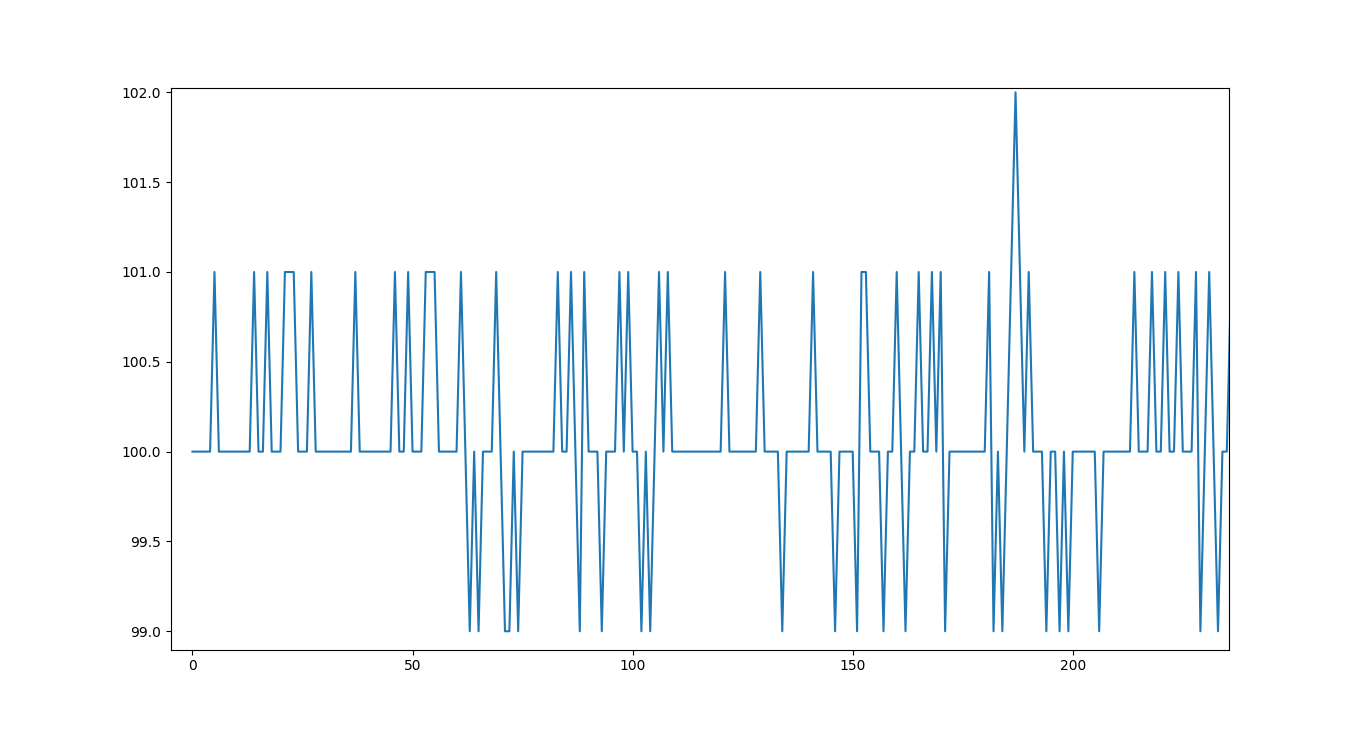
图3显示的跳跃性电压值更像是”噪音电波“而不是臭氧浓度的真实变化,与图3相比之下,我们更倾向于使用图4显示的数值图。
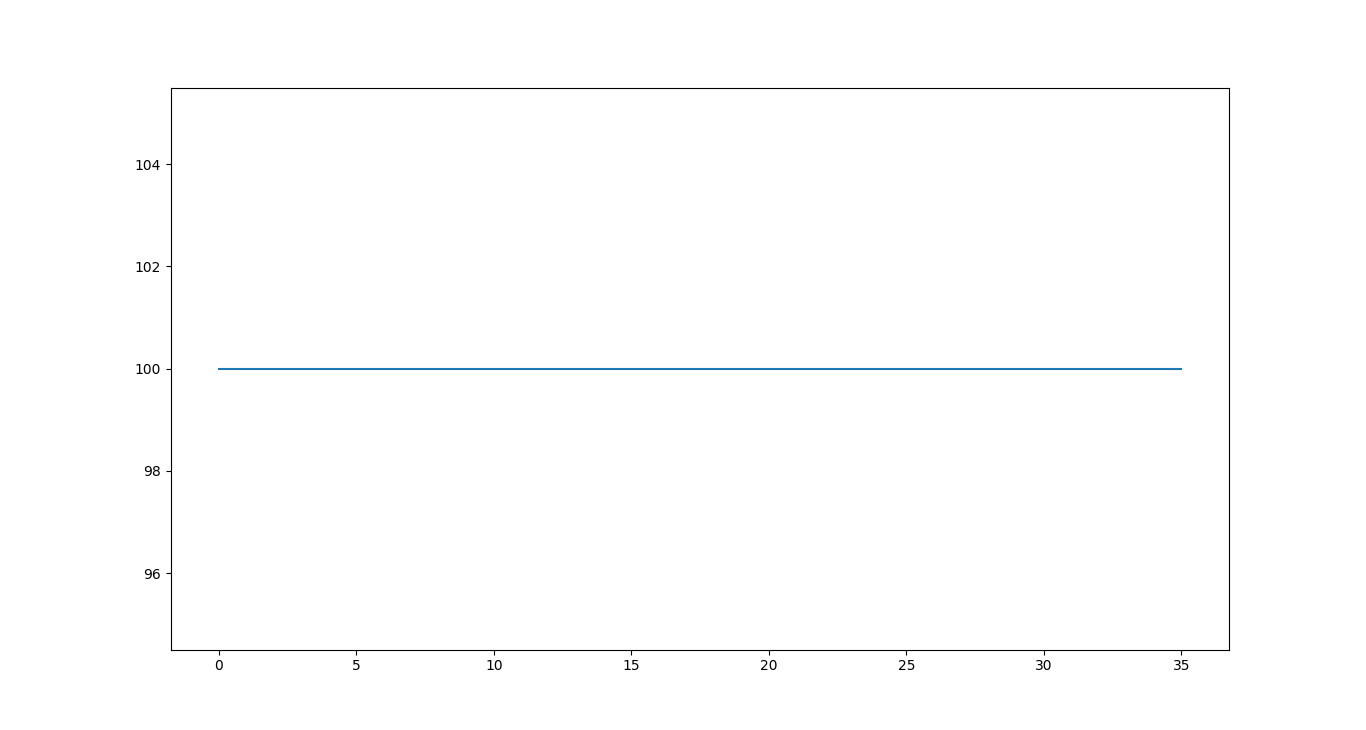
在图4中,只是取了30个样本组的平均值并四舍五入后,便得到一条完全平直的线。假设在我们实验时间间隔内(例如1秒)臭氧浓度是恒定的(那么,臭氧浓度变化的分辨率都低于传感器可解析程度),在这样处理数据的想法下,便可以解决数据凌乱的情况。
一方面,我们可以就取30个样本来完成实验数据统计,但另一方面,尝试一些不同的东西也会更有趣,而且能收获更多的学习经验。经过一番思考,接下来要解决的问题便是:
想要在相当短的时间内取样,通过实验研究目标监测气体,合理估计其实际浓度。假设传感器能够完成其工作,但是在监测中只受到一些凌乱数据的影响。
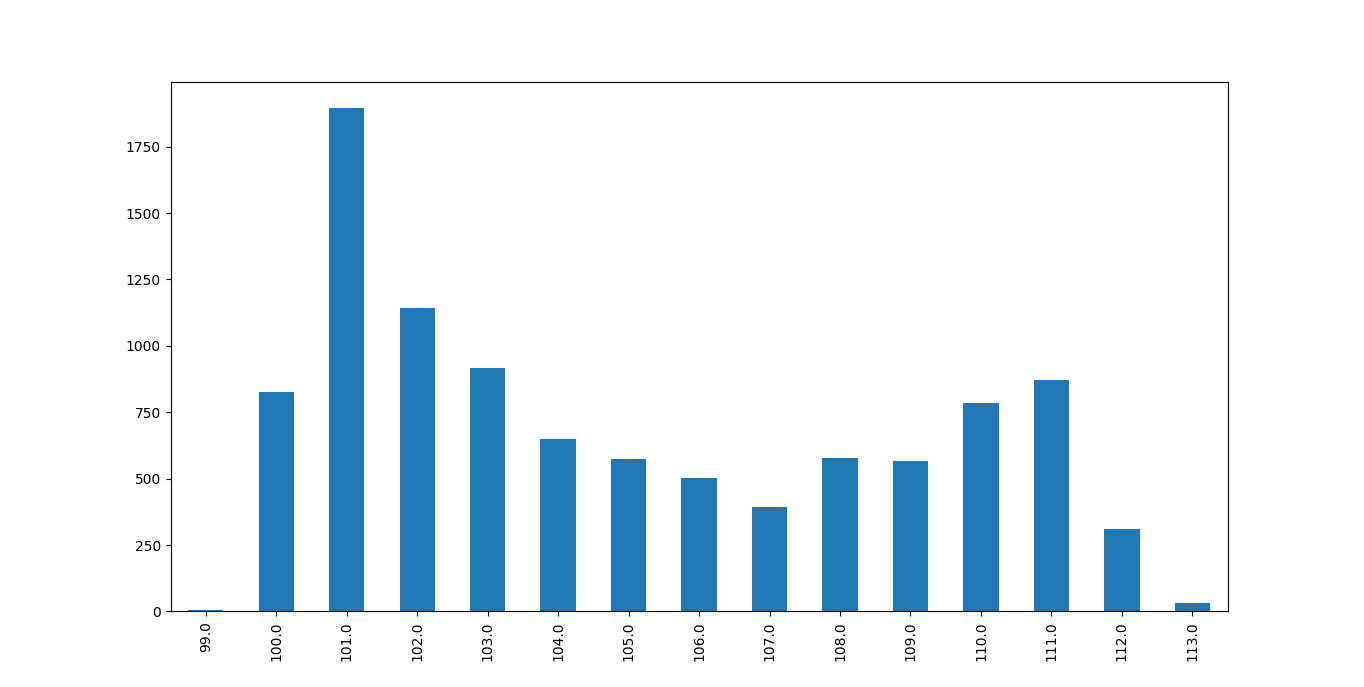
之所以想要在”相当短的时间“内取样源于想要尽快采集到目标监测气体浓度变化,因为监测浓度可能会发生变化(说实话,监测时容易没有耐心),图5便是在此情况下的示例,图中我不再只有一个“峰”值。对我来说,不宜太长时间采样这一点尤其重要,因为想要监测的东西太多。首先,从湿度,温度和臭氧起步,但希望能逐步添加二氧化氮,颗粒物,挥发性有机物和甲醛。因为之后还想要探究不同空气污染物之间的关联,所以在理想的环境下,上述这些监测实验会同步进行。此外,希望能够对监测同一目标的多个传感器进行比对。
为了简化要解决的问题,现在开始转化为数学统计问题:
在特定的时间间隔(例如秒)内得到一个真实的浓度平均值。那随后如何对估算的质量建模呢?
熟知一些统计学知识后[1] [2] 快速地让我开始想到置信区间,尤其是误差范围。假设所有传感器的监测同等重要,我们可以在固定的期望置信度(例如95%)下的时间预算(例如1秒)内,将所有传感器的误差范围之和最小化。
有了这些解题思路后,现在可以按照如下步骤来解决我们的问题:
- 对每个传感器每秒得到的标准偏差进行准确估算。
- 计算采样时间,从而在可接受的固定采样时间最大化的情况下,看看能得到多少个样本。
- 制定优化问题,以便一些编码程序可以求解(未来的挑战可能是由我们自己通过C++来解决 - 可能需要随时重新计算)。
优化问题如下所示:
$$
\begin{alignat}{2}
&\!\min_{n_x,\ x \in \text{传感器}} &\,& \sum_{x \in \text{传感器}} \frac {s_{x}} {\sqrt{n_{x}}} \\
\\
&\text{被限定于} & & \sum_{x\in\text{传感器}} n_x <= \text{时间预算} \\
\\
&\rlap{s_x\text{: 传感器x标准偏差的估算值}} \\
&\rlap{n_x\text{: 从传感器x采集的样本数}} \\
\end{alignat}
$$
基本上,我们希望将所有传感器的误差范围之和最小化。误差范围由以下方程式可得:
$$t * \frac s {\sqrt{n}}\\$$
其中t是恒定的选定置信度(例如95%)和由样本量定义的自由度的常数(只需在表中查找即可)。由于它不会影响我们的优化问题,因此我们可以将其删除。
对于WolframAlpha这样的编码程序, 处理上述的优化问题简直是小菜一碟,经过一些编码程序 后可得:
min (0.52 / sqrt(a) + 0.28 / sqrt(b) + 0.51 / sqrt(c)) s.t. a + b + c <= 8606
WolframAlpha对此处理的结果如下:
(a, b, c)≈(3252.96, 2141.52, 3211.44)
不出所料,在最低标准偏差下,要求传感器进行采集的样本数更少些。需要注意的是,我们从WolframAlpha编码程序中得到一个或多个局部最小值。想象下,假如在样本数更少以及标准偏差值更大的情况下,这样也许更容易去理解。比如,我们想在大街上随机找一些人问三个问题,(幸运的是!)我们又碰巧知道他们的标准偏差值分别为100、500和2000。我们总共只能问100个问题。于是可得:
min (100 / sqrt(a) + 500 / sqrt(b) + 2000 / sqrt(c)) s.t. a + b + c <= 100
WolframAlpha编码程序在以下位置找到一个局部最小值:
(8.85576, 25.8944, 65.2498)
因此,在美丽的城市街道上来回穿梭,你会问到问题一9次,问到问题二26次以及问到问题三65次。如果将每个问题被问到的次数平均分配,则最终的“误差范围”之和约为379次,而不是452次。对于第一个问题,你会发现大家的回答往往大致相同,而对于第三个问题,你会发现大家的回答大相径庭。于是,你便能信心十足地早早预料到大家对第一个问题的回答,但对第三个问题能预料到的却不多。
如前所述,事实也证明了,我们不需要考虑置信度。然而,我们可以用我们想要的数值(例如设置95%的置信度以及0.5的误差范围)来设置误差范围和置信度,并计算出在此设置下所需的样本数。其实实际操作时更容易些,因为我们可以简单地运用代数来求解,而不用制定优化问题。
但是,现在我们继续来运用已得结果,按照最简单的编码程序可执行以下操作:
int samplesToTake[] {3253, 2142, 3211};
int nrSensors = sizeof(analogSensorReaderArray)
/ sizeof(analogSensorReaderArray[0]);
for (auto i = 0; i < nrSensors; i++) {
StreamStats stats {};
auto sensor = analogSensorReaderArray[i];
for (auto j = 0; j < samplesToTake[i]; j++) {
stats.reportNumber(sensor.read());
}
Serial.print(stats.average());
Serial.print(",");
Serial.print(sensor.read());
Serial.print(",");
}
Serial.print(dht.readHumidity());
Serial.print(",");
Serial.print(dht.readTemperature());
Serial.println();上述编码中的samplesToTake是从WolframAlpha编码程序里复制粘贴(并四舍五入)而来。
不出所料,在给定的低标准偏差值下,所得结果差异并不大。对于MQ131低浓度传感器而言,最容易被观察到(可能需要放大来看):
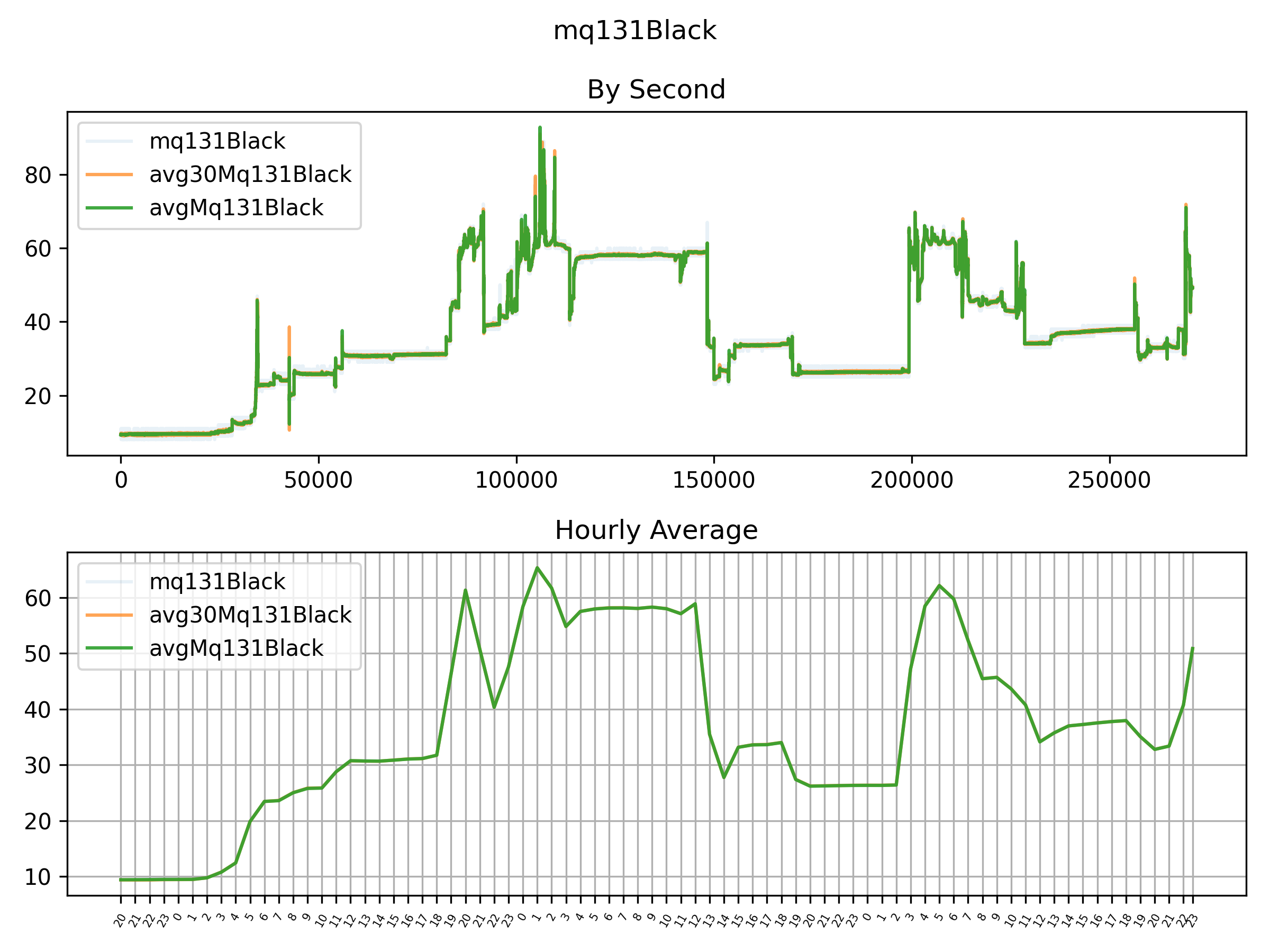
由于几乎同时从多个传感器中进行采样,并且我非常好奇关联矩阵,所以不得不一同查看:
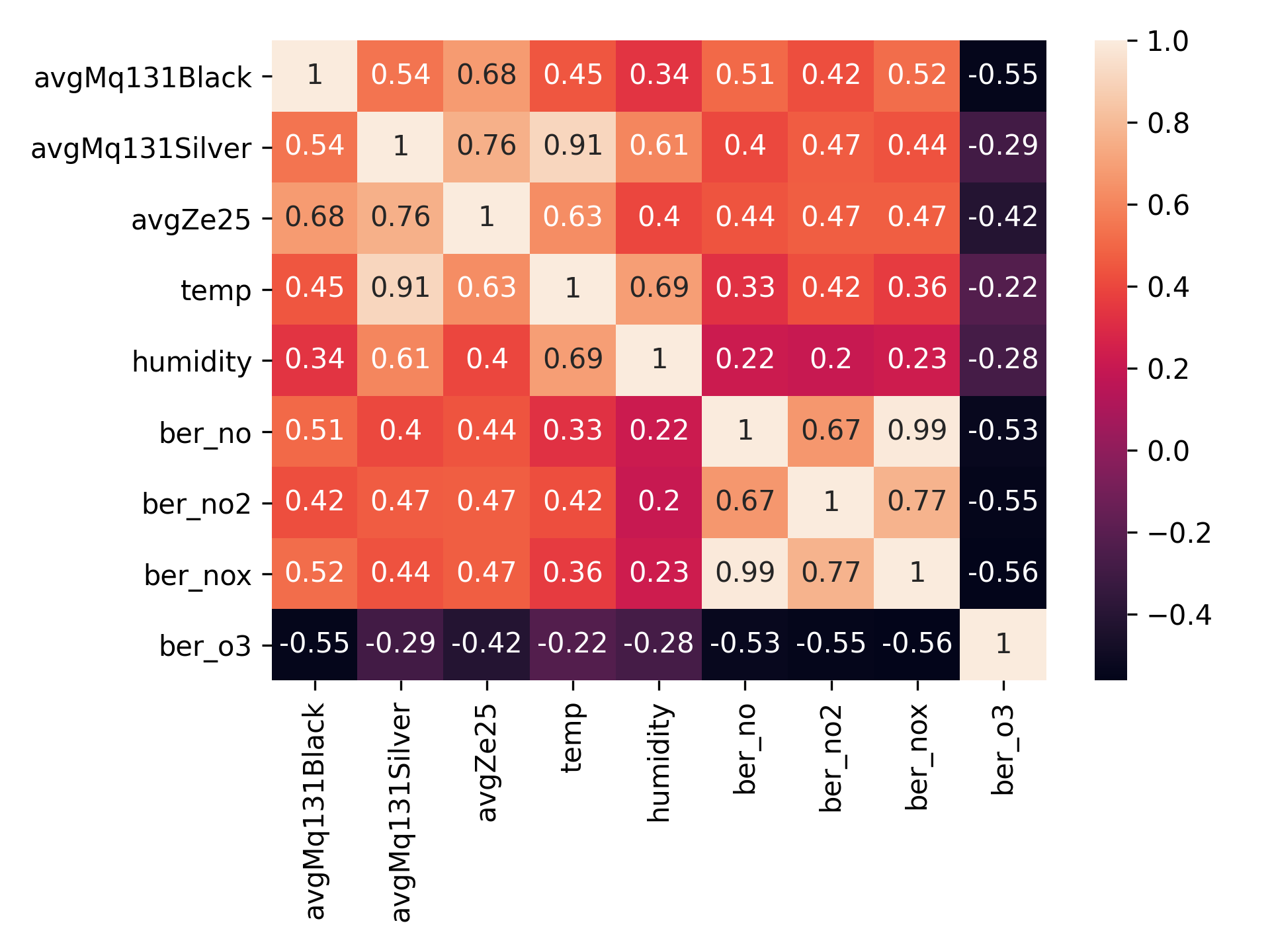
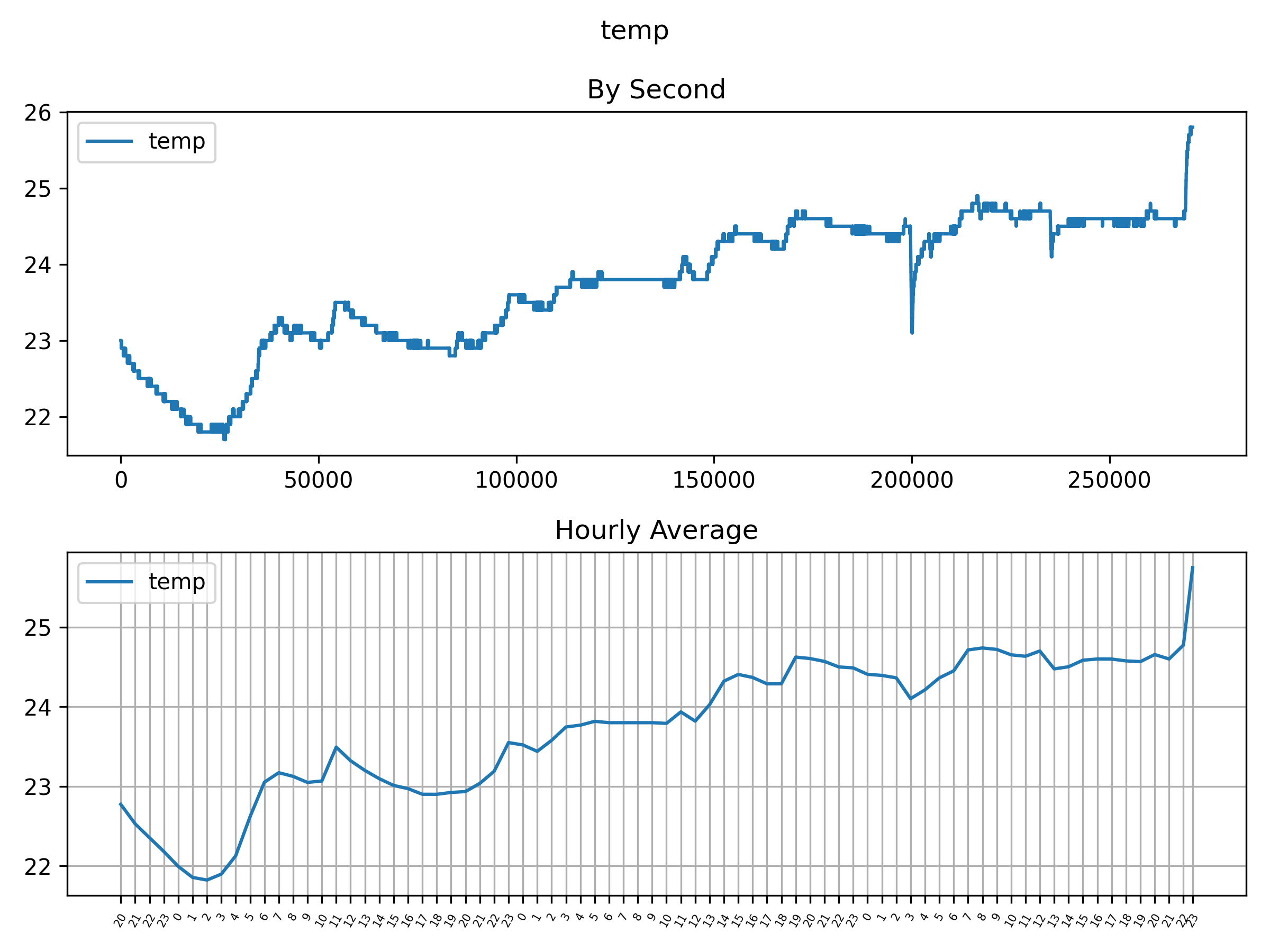
遗憾的是,这次Winsen ZE25-O3传感器的监测数据与柏林空气质量监测站给出的二氧化氮浓度值之间的相关性比之前实验所得相关性弱 (0.60 对比 0.47)。 但是,这可能跟温度有关,因为在整个监测过程中温度一直持续上升。 我还存有一丝疑虑是柏林空气质量监测效果不佳,例如,最近报告PM10颗粒物含量达几百μg/m3(即使将原因归结于撒哈拉沙漠吹来了大量风沙,这含量也可算是相当高了) 。
{kind=link}
有趣的是,所有传感器的监测数据均显示与室外臭氧浓度值负相关。我认为,这其中一部分的原因是臭氧浓度与氮氧化物浓度负相关,并且所有传感器也只对占主导地位的氮氧化物浓度敏感。因此,当臭氧浓度下降而氮氧化物浓度上升时,监测到的数值更大。从实验中,我们可以发现监测结果与温度有高度相关性。实际上,我们的MQ131 银色(高浓度臭氧传感器)与温度具有非常强烈的相关性(0.91)。可能是因为这个传感器并不是用于监测环境中臭氧浓度的(因此传感器基本上都显示臭氧浓度值为零),但仍显示出对温度差的敏感度。关联矩阵对于建立大量假设非常有用(在这里我有点懒惰,当然,查看p值来了解可多大程度地信任关联性,这并无坏处 - 比如可参见关于Winsen ZE25-O3的旧帖子)!
编码程序
完整的编码程序可以前往Github查阅。除了刚刚提到的编码程序外,这部分就没有额外想要进一步探讨的内容了。也许就对如何在StreamStats.cpp中计算方差可能还有点兴趣。想要解决这个问题的思路受启发于StackExchange上的讨论,讨论中提到了Donald Knuth编著的“计算机编程艺术”一书,而此书中就阐述了一种解决这个问题的方法。(因为我们在Arduino上运行编码程序)在设置时间预算时,我不希望因为存储记忆空间被占用太快而成为限制因素,因此希望捕捉到每一个流出的数值,然后计算平均值和方差。
结论
本次实验展示了如何将传感器采样视为一个数学统计问题,然后又转化为建立优化问题:我们希望在时间预算(我们所希望的采样时间最大化值)内将所有传感器的误差范围之和最小化。于是,我们找到了一种解决方案,通过估算标准偏差,在给定时间预算的情况下计算能够采集的样本数量,并建立一个WolframAlpha能够处理的优化问题,以便其为我们求解。在这个解决方案中可以得知每个传感器能够采集多少个样本。
虽说并不需要完全按照这个解决方案来执行-因为就算每个传感器采集30个样本,似乎也能完成整个实验-但是这个解决方案让我感到很有趣,我希望你,和我一样能从这个实验中学到一些。
重点注意的是,本文所提出的解决方案源于我个人思考所得。如果你有兴趣进行更深入的研究,可以查阅统计传感器校准算法,这也是一本我想找时间认真拜读的书,看看是否可以从中找到一些其他可以应用的思路。
未来计划
我越来越想要探讨温度和湿度对传感器的补偿影响。主要想试试看在假设湿度和温度对传感器电压有影响并具有补偿作用的情况下,是否能增强我们实验传感器监测数据与政府传感器监测数据的相关性。我是一名机器学习粉,所以相信机器学习可以在这里被运用到。
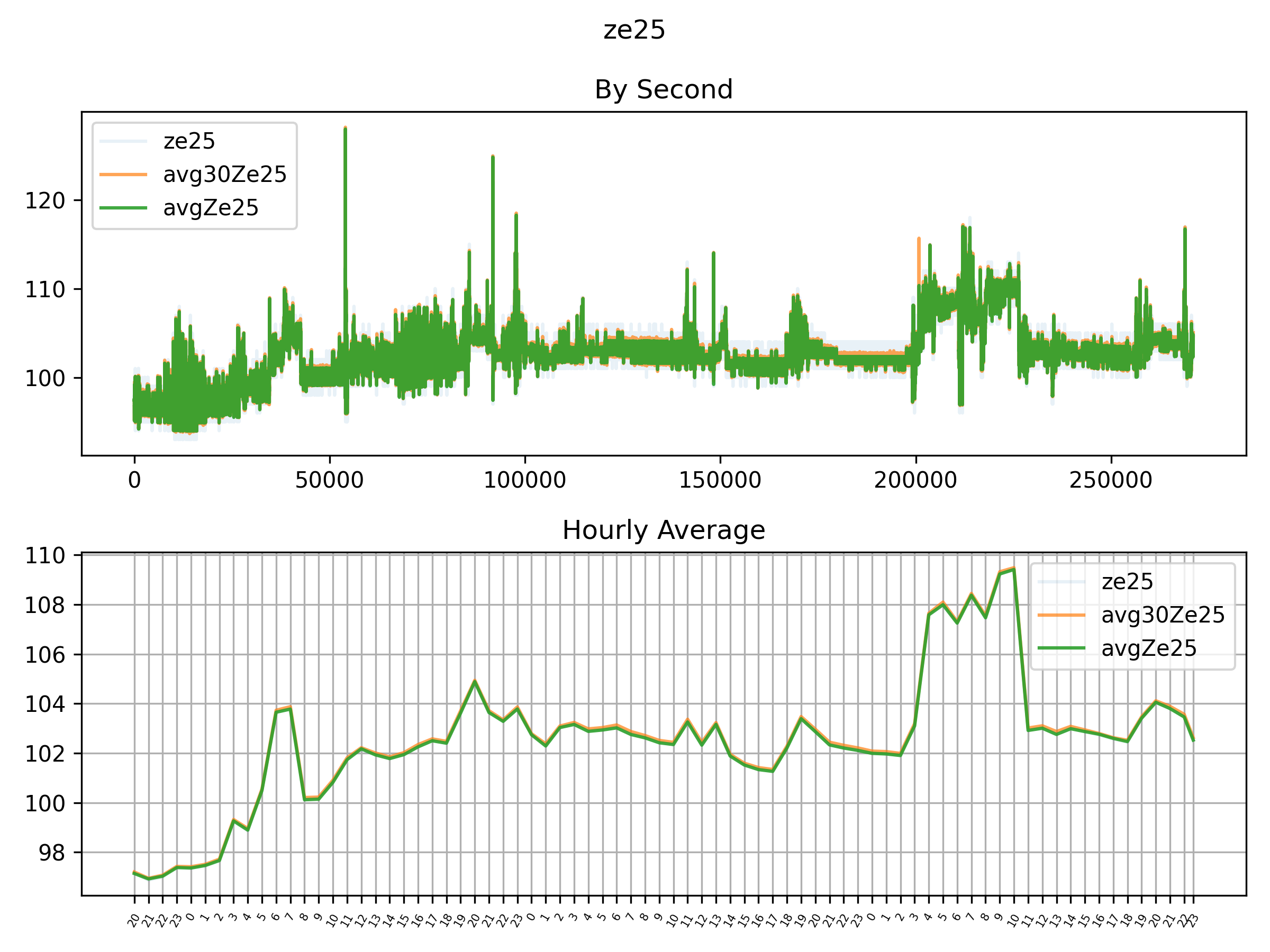
(在Arduino上)运用C ++来进行优化问题对我而言同样有兴趣,这样便可以连续性地重新校准(也能锻炼我处理优化问题)。根据Winsen ZE25-O3监测到的凌乱数据图,我怀疑标准偏差可能确实有所变化。
{kind=link}
参考文献
[1] L. Sullivan, Confidence Intervals. Boston University School of Public Health, [Online]. Available: https://sphweb.bumc.bu.edu/otlt/mph-modules/bs/bs704_confidence_intervals/bs704_confidence_intervals_print.html.
[2] J. S. Milton and J. C. Arnold, Introduction to probability and statistics: Principles and applications for engineering and the computing sciences. McGraw-Hill.